
Estudios de cohortes.

Se describen las características de los estudios de cohortes, sus medidas de asociación e impacto y sus segos más característicos.
¡Qué tíos esos romanos!. Iban, veían y vencían. Con esas legiones, cada una con sus diez cohortes, cada cohorte con sus casi quinientos romanos con su falda y sus sandalias de correas. Las cohortes eran grupos de soldados que estaban al alcance de la arenga de un mismo jefe y siempre avanzaban, nunca retrocedían. Así se puede conquistar la Galia (aunque no en su totalidad, como es bien sabido).
Características de los estudios de cohortes
En epidemiología, una cohorte es también un grupo de personas que comparten algo, pero en lugar de ser la arenga de su jefe es la exposición a un factor que se estudia a lo largo del tiempo (tampoco son imprescindibles ni la falda ni las sandalias).
Así, un estudio de cohortes es un tipo de diseño observacional, analítico, de direccionalidad anterógrada y de temporalidad concurrente o mixta que compara la frecuencia con la que ocurre un determinado efecto (generalmente una enfermedad) en dos grupos diferentes (las cohortes), uno de ellos expuesto a un factor y otro no expuesto al mismo factor (ver figura adjunta).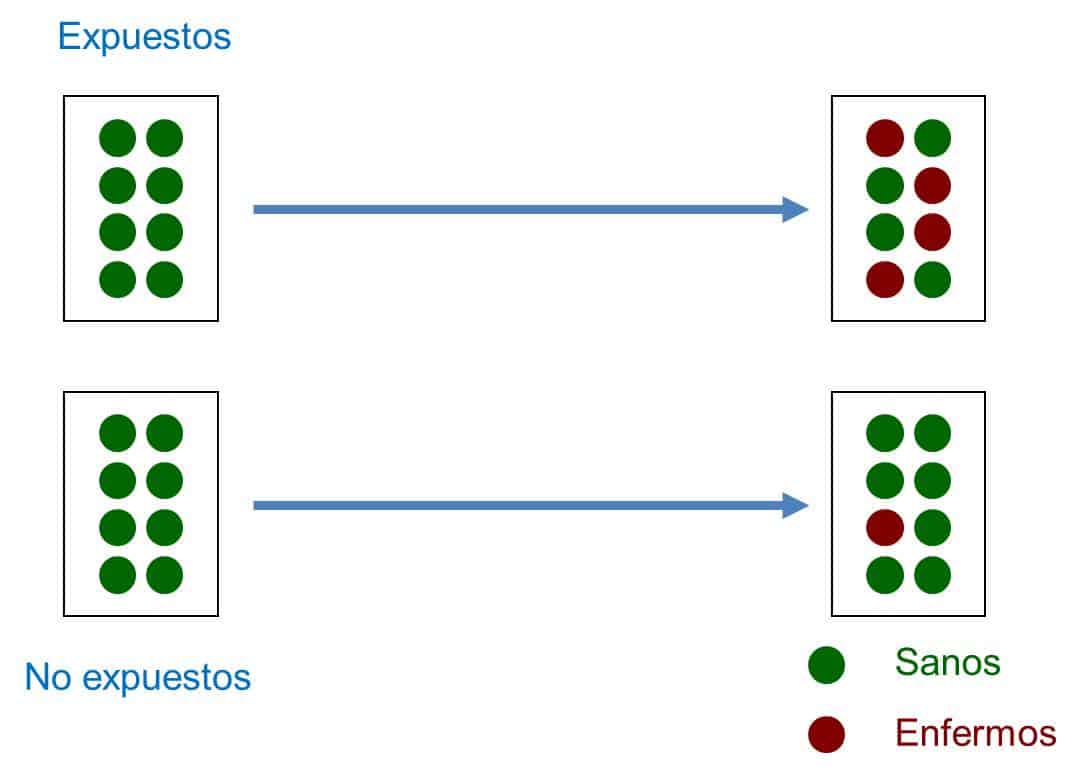
Por lo tanto, el muestreo está relacionado con la exposición al factor. Ambas cohortes se estudian a lo largo del tiempo, por lo que la mayor parte de los estudios de cohortes son prospectivos o de temporalidad concurrente (van hacia delante, como las cohortes romanas). Sin embargo, es posible hacer estudios de cohortes retrospectivos una vez ocurridos tanto la exposición como el efecto.
En estos casos, el investigador identifica la exposición en el pasado, reconstruye la experiencia de la cohorte a lo largo del tiempo y asiste en el presente a la aparición del efecto, por lo que son estudios de temporalidad mixta.
Podemos clasificar también los estudios de cohortes según utilicen un grupo de comparación interno o externo. En ocasiones podemos utilizar dos cohortes internas pertenecientes a la misma población general, clasificando a los sujetos en una u otra cohorte según el nivel de exposición al factor. Sin embargo, otras veces la cohorte expuesta nos interesará por su alto nivel de exposición, por lo que preferiremos seleccionar una cohorte externa de sujetos no expuestos para realizar la comparación entre ambas.
Otro aspecto importante a la hora de clasificar los estudios de cohortes es el momento de inclusión de los sujetos en el estudio. Cuando solo seleccionamos los sujetos que cumplen los criterios de inclusión al comienzo del estudio hablamos de cohorte fija, mientras que hablaremos de cohorte abierta o dinámica cuando siguen entrando sujetos en el estudio a lo largo del seguimiento. Este aspecto tendrá importancia, como veremos después, a la hora de calcular las medidas de asociación entre exposición y efecto.
Por último, y como curiosidad, también podemos hacer un estudio con una sola cohorte si queremos estudiar la incidencia o la evolución de una determinada enfermedad. Aunque siempre podemos comparar los resultados con otros datos conocidos de la población general, este tipo de diseños carece de grupo de comparación en sentido estricto, por lo que se engloba dentro de los estudios descriptivos longitudinales.
Al realizarse un seguimiento a lo largo del tiempo, los estudios de cohortes permiten calcular la incidencia del efecto entre expuestos y no expuestos, calculando a partir de ellas una serie de medidas de asociación y de medidas de impacto características.
Medidas de asociación en estudios de cohortes
En los estudios con cohortes cerradas en las que el número de participantes es fijo, la medida de asociación es el riesgo relativo (RR), que es la proporción entre la incidencia de expuestos (Ie) y no expuestos (I0): RR = Ie/I0.
Como ya sabemos, el RR puede valer desde 0 a infinito. Un RR=1 quiere decir que no hay asociación entre exposición y efecto. Un RR<1 quiere decir que la exposición es un factor de protección frente al efecto. Por último, un RR>1 indica que la exposición es un factor de riesgo, tanto mayor cuanto mayor sea el valor del RR.
El caso de los estudios con cohortes abiertas en los que pueden entrar y salir participantes a lo largo del seguimiento es un poco más complejo, ya que en lugar de incidencias calcularemos densidades de incidencia, término que hace referencia al número de casos del efecto o enfermedad que se producen referidas al número de personas seguidas por tiempo de seguimiento de cada una (por ejemplo, número de casos por 100 personas-año). En estos casos, en lugar del RR calcularemos la razón de densidades de incidencia, que es el cociente de la densidad de incidencia en expuestos dividida por la densidad en no expuestos.
Medidas de impacto en estudios de cohortes
Estas medidas nos permiten estimar la fuerza de la asociación entre la exposición al factor y el efecto, pero no nos informan sobre el impacto potencial que tiene la exposición sobre la salud de la población (el efecto que tendría eliminar ese factor sobre la salud de la población). Para ello, tendremos que recurrir a las medidas de riesgo atribuible, que pueden ser absolutas o relativas.
Las medidas absolutas de riesgo atribuible son dos. La primera es el riesgo atribuible en expuestos (RAE), que es la diferencia entre la incidencia en expuestos y no expuestos y representa la cantidad de incidencia que puede ser atribuida al factor de riesgo en los expuestos. La segunda es el riesgo atribuible poblacional (RAP), que representa la cantidad de incidencia que puede ser atribuida al factor de riesgo en la población general.
Por su parte, las medidas relativas 
En la tabla que os adjunto podéis ver las fórmulas que se emplean para el cálculo de estas medidas de impacto.
El problema de estas medidas de impacto es que pueden ser, en ocasiones, difíciles de interpretar por parte del clínico. Por ese motivo, e inspirados en el cálculo del número necesario a tratar (NNT) de los ensayos clínicos, se han ideado una serie de medidas denominadas números de impacto, que nos dan una idea más directa del efecto del factor de exposición sobre la enfermedad en estudio. Estos números de impacto son el número de impacto en expuestos (NIE), el número de impacto en casos (NIC) y el número de impacto de los casos expuestos (NICE).
Empecemos por el más sencillo. El NIE sería el equivalente al NNT y se calcularía como el inverso de la reducción absoluta de riesgos o de la diferencia de riesgos entre expuestos y no expuestos. El NNT es el número de personas que deben ser tratadas para prevenir un caso en comparación con el grupo control. El NIE representa el número medio de personas que tienen que exponerse al factor de riesgo para que se produzca un nuevo caso de enfermedad en comparación con las personas no expuestas. Por ejemplo, un NIE de 10 significa que de cada 10 expuestos se producirá un caso de enfermedad atribuible al factor de riesgo estudiado.
El NIC es el inverso de la FAP, así que define el número medio de personas enfermas entre las que un caso es debido al factor de riesgo. Un NIC de 10 quiere decir que por cada 10 enfermos de la población, uno es atribuible al factor de riesgo en estudio.
Por fin, el NICE es el inverso de la FAE. Es el número medio de enfermos entre los que un caso es atribuible al factor de riesgo.
En resumen, estas tres medidas miden el impacto de la exposición entre todos los expuestos (NIE), entre todos los enfermos (NIC) y entre todos los enfermos que han estado expuestos (NICE). Será de utilidad que intentemos calcularlos si los autores del estudio no lo hacen, ya que nos darán una idea del impacto real de la exposición sobre el efecto. En la segunda tabla os pongo las fórmulas que podéis utilizar para obtenerlos.
Como colofón a los tres anteriores, podríamos estimar el efecto de la exposición en toda la población calculando el número de impacto en la población (NIP), para lo cual no tenemos más que hacer el inverso del RAP. Así, un NIP de 3000 quiere decir que por cada 3000 sujetos de la población se producirá un caso de enfermedad debida a la exposición.
Sesgos de los estudios de cohortes
Otro aspecto que debemos tener en cuenta al tratar de los estudios de cohortes es su riesgo de sesgos. En general, los estudios observacionales tienen mayor riesgo de sesgo que los experimentales, además de ser susceptibles a la influencia de factores de confusión y de variables modificadoras de efecto.
El sesgo de selección debe considerarse siempre, ya que puede comprometer la validez interna y externa de los resultados del estudio. La dos cohortes deben ser comparables en todos los aspectos, además de ser representativas de la población de la que proceden.
Otro sesgo muy típico de los estudios de cohortes es el sesgo de clasificación, que se produce cuando se realiza una clasificación errónea de los participantes en cuanto a su exposición o a la detección del efecto (en el fondo no es más que otro sesgo de información). El sesgo de clasificación puede ser no diferencial cuando el error se produce al azar de forma independiente de las variables de estudio.
Este tipo de sesgo de clasificación va a favor de la hipótesis nula, o sea, que nos dificulta detectar la asociación entre exposición y efecto, si es que esta existe. Si, a pesar del sesgo, detectamos la asociación, pues no pasará nada malo, pero si no la detectamos no sabremos si es que no existe o si no la vemos por la mala clasificación de los participantes. Por otra parte, el sesgo de clasificación es diferencial cuando se realiza de forma diferente entre las dos cohortes y tiene que ver con alguna de las variables del estudio. En este caso no hay perdón ni posibilidad de enmienda: la dirección de este sesgo es impredecible y compromete de forma mortal la validez de los resultados.
Por último, siempre debemos estar atentos a la posibilidad de que haya sesgo de confusión (por variables de confusión) o sesgo de interacción (por variables modificadoras de efecto). Lo ideal es prevenirlos en la fase de diseño, pero no está de más controlar los factores de confusión en la fase de análisis, fundamentalmente mediante análisis estratificados y estudios multivariados.
Nos vamos…
Y con esto llegamos al final de esta entrada. Vemos, pues, que los estudios de cohortes son muy útiles para calcular la asociación y el impacto entre efecto y exposición pero, cuidado, no sirven para establecer relaciones causales. Para eso son necesarios otros tipos de estudios.
El problema con los estudios de cohortes es que son difíciles (y costosos) de realizar de forma adecuada, suelen requerir muestran grandes y, a veces, periodos de seguimiento prolongados (con el consiguiente riesgo de pérdidas). Además, son poco útiles para enfermedades raras. Y no debemos olvidar que no nos permiten establecer relaciones de causalidad con la seguridad suficiente, aunque para ello sean mejores que sus primos los estudios de casos y controles, pero esa es otra historia…