
Valor E.

Se revisa cómo la confusión no medida puede distorsionar las asociaciones en estudios observacionales y presentan los parámetros para cuantificar este efecto. Se explica cómo el valor E cuantifica la fuerza mínima que debería tener un confundidor no medido para explicar por completo un efecto observado o hacerlo compatible con la ausencia de asociación. Finalmente, se comentan de forma resumida sus extensiones a distintas medidas de efecto y su papel complementario a los valores de p en la lectura crítica.
En casi todos los pueblos hay una rotonda maldita. Desde que la pusieron (dice la gente) hay más accidentes, más atascos, más divorcios y hasta menos plazas de aparcamiento. La rotonda se convierte en la culpable oficial de todo: está ahí, se ve, y es comodísima para señalar con el dedo. Nadie se plantea que, de paso, ha cambiado el tráfico, el alumbrado, el tipo de coches, los horarios… pero da igual: tener una causa sencilla nos deja mucho más tranquilos que admitir que quizá no entendemos del todo lo que está pasando.
Con los estudios observacionales hacemos algo parecido. Vemos que las personas que toman X tienen menos de Y, o que quienes hacen Z mueren más que los que no, y nuestro cerebro salta directo a la causalidad: “X protege”, “Z mata”. Pero esos estudios, en realidad, lo que capturan es asociación, no causalidad. Y esa asociación siempre puede ser culpa de un factor de confusión que no conocemos, no hemos medido o no hemos sabido ajustar. Un “detalle” que se ha quedado fuera del modelo… pero no fuera de la realidad.
Por eso solo los ensayos clínicos pueden demostrar causalidad, porque damos por hecho que la aleatorización reparte por igual los factores de confusión, conocidos y desconocidos, entre el grupo de intervención y el de control. De lo cual, dicho sea de paso, tampoco tenemos una garantía absoluta.
Así que, en esta entrada, vamos a reflexionar sobre la diferencia entre buscar causalidad y conformarse con asociaciones bonitas. Y, en concreto, de cómo podemos hacernos una pregunta incómoda: ¿cómo de fuerte tendría que ser ese factor de confusión desconocido para cargarse la relación que hemos encontrado? Ahí entra en escena nuestro protagonista con nombre de gadget estadístico: el valor E, una forma de ponerle número al fantasma y decidir si nos creemos la historia causal… o si la rotonda, una vez más, igual no tiene la culpa de todo.
Confusión
Antes de nada, vamos a recordar que son los factores de confusión.
Un factor de confusión es una variable que está relacionada a la vez con la exposición y con el efecto, pero que no está en la cadena causal directa entre los dos. El gran peligro de los factores de confusión es que, si no los medimos o los medimos mal, pueden fabricar asociaciones falsas: hacen que parezca que la exposición “protege” o “favorece” la producción del resultado, cuando en realidad la diferencia se debe a otra cosa que va de paquete.
La consecuencia de la confusión desconocida o mal controlada es que el estudio puede devolver un indicador de asociación entre exposición y efecto, pero ese índice puede estar contando, sobre todo, la historia del confundidor y no la de la exposición que nos interesa.
Imaginad que cae en vuestras manos un estudio de cohortes que afirma que “hacer ejercicio reduce un 75% el riesgo de fildulastrosis”. La fildulastrosis es una enfermedad temible, cuyo nombre suena a algo entre enfermedad tropical y castigo bíblico, así que os quedáis con la idea importante: el gimnasio os salva la vida.
El problema es que los estudios de cohortes, como ya sabemos, son observacionales. En este caso, el estudio compara gente que va al gimnasio con gente que prefiere el sofá, y encuentra que los deportistas tienen un riesgo relativo (RR) de 0,25 para fildulastrosis frente a los sedentarios. Cuatro veces menos riesgo. Los autores concluyen algo así como que “estos resultados sugieren un posible efecto protector del ejercicio físico”. Así que nos ponemos a buscar mallas en internet.
Pero cuando lo pensamos dos veces, nos damos cuenta de que, entre el sofá y la cinta de correr, hay mucha vida. En nuestro estudio imaginario nadie ha medido un detalle aparentemente inocente: el consumo compulsivo de realities televisivos. Resulta que los grandes fans de “La Isla de los Cuñados Famosos” tienden a pasar la noche pegados a la pantalla, duermen poco, comen cualquier cosa que encuentran a mano y, en general, no pisan el gimnasio ni para ir al baño.
Por simplificar, digamos que entre los que no hacen ejercicio, un 60% es adicto a realities, mientras que entre los deportistas solo lo es un 20%. Eso ya nos dice que la variable “ver realities” está asociada con la exposición “no hacer ejercicio”. Y, para rematar, supongamos que los adictos a realities tienen cinco veces más riesgo de desarrollar fildulastrosis que quienes prefieren leer prospectos de medicamentos antes de acostarse. Esa variable que nadie incluyó en el cuestionario tiene nombre y apellidos: es un factor de confusión no medido.
Cuantificar lo desconocido
Hasta aquí la historia es más o menos conocida. En los estudios observacionales casi nunca podemos medir absolutamente todo: hábitos raros, rasgos de personalidad, pequeños detalles socioeconómicos… Siempre puede haber algo que esté asociado tanto con la exposición como con el desenlace y que esté empujando la asociación sin que nos demos cuenta.
Y eso significa que la asociación que vemos puede no ser causal. Así que nos podríamos plantear una pregunta muy concreta: si existe un confundidor desconocido, como nuestro reality, ¿qué tan fuerte tendría que ser su efecto sobre la exposición y sobre el efecto para explicar por completo la asociación observada?
Podemos empezar por traducir a números la fuerza del confundidor. Volvamos a nuestro ejemplo. Podemos describir cuán potente es “ver realities” para distorsionar el resultado del estudio con dos RR.
Un RR resume cómo cambia la probabilidad de la exposición cuando cambias el nivel del confundidor; en nuestro caso, cuánto aumenta la probabilidad de ser sedentario si eres fan de realities comparado con si no lo eres. Si entre los fans de realities el 70% no hace ejercicio y entre los no fans solo el 30% es sedentario, la razón de riesgos exposición–confundidor (RR) sería aproximadamente 0,70 / 0,30, es decir, algo más de 2.
Vamos a llamar a este RR de exposición en función del confundidor RR_EC (exposición-confundidor).
El segundo RR resume cuánto cambia el riesgo del resultado del estudio cuando cambia el nivel del confundidor; es decir, cuánto aumenta el riesgo de fildulastrosis en fans de realities respecto a quienes no lo son, ajustando por lo que ya hemos medido. Si ahí tenemos un factor 5, diríamos que RR_RC (resultado-confundidor) = 5.
Con estas dos cifras (RR_EC y RR_RC) ya podemos calcular cuánto podría deformar, como máximo, la estimación de la asociación un confundidor así. Para ello, vamos a calcular un parámetro nuevo, que suele denominarse B (de bias, sesgo en inglés). La fórmula para obtenerlo es la siguiente:
B = RR_RC x RR_EC / (RR_RC + RR_EC -1)
No os dejéis impresionar por la fórmula, en realidad es bastante sencilla. El parámetro B es el que nos puede estar inflando el efecto si hay un confusor no medido, así que lo calculamos para estimar cuál sería la asociación real entre exposición y efecto sin ese factor de confusión.
En el numerador tenemos los productos de los dos RR, el de la exposición y el resultado con el factor de confusión. Esto es lógico, ya que para que el factor de confusión distorsione la relación entre exposición y efecto tiene, por definición, que influir en los dos. Si sustituís en la fórmula uno de los dos RR = 1 (solo se relaciona con exposición o con efecto), B = 1. Conclusión: si no se asocia con los dos, el confundidor no puede sesgar la medida de asociación (no habría confusión). Por otra parte, cuanto mayor sea el producto de los dos RR, mayor será el sesgo de la estimación.
En cuanto al denominador, no os preocupéis mucho por él. Es una argucia matemática para que el valor de B no se dispare demasiado y para no obtener valores imposibles de RR.
Vamos a hacer un ejemplo con números concretos para ver cómo aplicamos el valor de B. Supongamos que RR_EC = 3 (los fans de realities tienen tres veces más probabilidad de ser sedentarios) y que RR_RC = 5 (tienen cinco veces más riesgo de fildulastrosis). El valor de B sería de:
B = 5 x 3 / (5 + 3 – 1) = 15 / 7 = 2,1.
Esto quiere decir que, como mucho, el factor de confusión no medido podría estar inflando (o sesgando) el RR observado por un factor de 2,1, pero no más.
Si el estudio observa que los sedentarios tienen un RR = 4 de fildulastrosis respecto a los deportistas, el efecto “limpio de realities” no podría bajar de
RR = 4 / 2,1 = 1,9
Es decir, incluso con un confundidor muy potente, la asociación no desaparece: sigue habiendo casi el doble de riesgo en los sedentarios. Nuestro reality explica parte del desastre, pero no todo.
Si, en cambio, con otras combinaciones de RR_EC y RR_RC el valor de B fuese tan grande que el RR observado dividido por B cayera por debajo de 1, entonces sí que el confundidor podría explicar completamente la asociación sin necesidad de un efecto causal del ejercicio.
Para acabar con este apartado, fijaos que, hasta ahora, solo hemos hablado de supuestos factores de riesgo, con RR > 1. En los casos en que la asociación observada sea protectora, RR < 1, multiplicaremos por B, en lugar de dividir, para estimar el posible sesgo de la medición debida a un confusor no medido.
El valor E
Hasta ahora hemos tratado de contestar a la pregunta de qué sesgo en la medición del RR produciría un factor de confusión no medido que tuviese un valor de fuerza de asociación determinado. Claro que esto lo hacemos totalmente a ojo, porque el valor de confusión no medido es, que nadie se sorprenda, desconocido, por lo que nos “inventamos” sus posibles valores.
Una forma más elegante de proceder sería darle la vuelta a la pregunta, para intentar dilucidar qué fuerza mínima debería tener un confundidor para explicar por completo la asociación que vemos en el estudio. Y la respuesta a esta pregunta viene de la mano del protagonista de esta entrada, el valor E.
El valor E, cuando observamos RR > 1, se define con la siguiente fórmula:
valor E = RR + Raíz cuadrada(RR X (RR – 1))
Cuando RR es protector, menor que 1, se toma primero el inverso del RR y se usa la misma operación.
Parece una fórmula mágica, que no vamos a explicar, pero su interpretación es muy mundana: es el RR mínimo que deberán tener ambas asociaciones del confundidor, la de la exposición y la del resultado, para que un único factor de confusión no medido pueda explicar completamente la asociación observada.
En el plano imaginario de todas las parejas posibles de RR_EC y RR_RC que podrían sesgar el efecto observado, el valor E identifica el punto en el que esos dos RR son iguales y, además, tan pequeños como sea posible.
Vamos a aplicarlo a nuestro gimnasio. Suponed que el estudio encuentra que quienes hacen ejercicio tienen un cuarto del riesgo de fildulastrosis que los sedentarios (RR = 0,25). Como es un efecto protector, empezamos tomando el inverso: 1 / RR = 4. Ahora aplicamos la fórmula y obtenemos un valor de E = 7,4.
La interpretación de este valor E sería la siguiente: solo un confundidor no medido que multiplicara por unas siete veces la probabilidad de hacer ejercicio y, al mismo tiempo, multiplicara por unas siete veces el riesgo de fildulastrosis podría, él solito, explicar por completo la asociación observada. Cualquier cosa más flojita que eso podría reducir el efecto, pero no borrarlo.
Esta estimación puntual es muy elegante, pero ya sabéis que a mí me gusta sufrir con los intervalos de confianza. Imaginad que el 95% de confianza para ese RR = 0,25 es de 0,10 a 0,60. El límite más cercano al nulo (que es 1) es 0,60. De nuevo hacemos el truco del inverso (obtenemos aproximadamente 1,66) y aplicamos la fórmula. Obtenemos un valor E para el límite del intervalo de unos 2,7. Esto significa que un confundidor no medido que estuviera asociado tanto con el ejercicio como con la fildulastrosis mediante RR de, al menos, 2,7 podría empujar ese límite hasta 1 y dejar el efecto “compatible con la ausencia de asociación”. Cualquier confundidor menos potente no lo conseguiría.
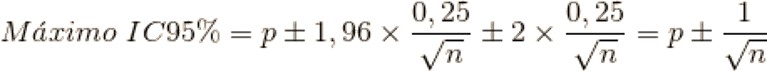{kind=link}
Lógicamente, si el RR > 1, tomaríamos el límite inferior del intervalo de confianza para hacer los cálculos. Siempre el límite más próximo al valor nulo, que es 1.
Fijaos bien en la diferencia de mensaje que nos transmite el valor E. Un valor E elevado del estimador puntual nos dice que el efecto es muy robusto; haría falta un confusor no medido con una fuerza de asociación enorme para explicarla si la asociación observada no fuese real.
El valor E del límite del intervalo más cercano a 1 será más modesto; con un confundidor de fuerza moderada el intervalo ya podría llegar a tocar el 1. Los dos números cuentan historias complementarias y mucho más informativas que un p-valor diminuto en solitario.
Actores secundarios, pero de lujo
Hasta ahora hemos hablado de RR, pero en los estudios observacionales muchas veces lo que obtenemos son odds ratios (OR), hazard ratios (HR), razones de tasas o diferencias de medias. El truco del valor E consiste en encontrar una forma razonable de traducir cualquiera de esas medidas a algo parecido a un RR para poder utilizarlo en la misma fórmula.
Si la prevalencia del desenlace es baja, inferior al 10 o 15%, la OR y la HR se parecen bastante al RR y se pueden usar directamente. Si el desenlace es frecuente y solo tenemos una OR, se puede usar una aproximación, por ejemplo, tomar la raíz cuadrada de la OR como si fuera el RR aproximado y calcular a partir de ahí.
Con HR y eventos comunes hay fórmulas un poco más enrevesadas que permiten hacer algo equivalente. Y cuando lo que tenemos son diferencias de medias, se puede estandarizar el tamaño del efecto e interpretar eso aproximadamente como una cierta razón de riesgos mediante una transformación exponencial.
Todo esto suena complicado, pero la filosofía es la misma: tenemos una medida de efecto, la traducimos a un RR aproximado, calculamos el valor E con la fórmula y acabamos con un número que responde a la misma pregunta: ¿cuán fuerte tendría que ser el confundidor desconocido para destrozar nuestro resultado?
Nos vamos…
Y aquí vamos a dejar por hoy de darle vueltas a la rotonda maldita de los factores de confusión no medidos.
Antes de irnos, quiero recalcar que la gracia del valor E no está solo en el número, sino en cómo lo interpretamos. Hay que compararlo con asociaciones que conocemos o intuimos en nuestro propio estudio. Si las covariables medidas más potentes tienen RR de 2 o 3 con el desenlace y de 1,5 o 2 con la exposición, pensar en un confundidor no medido que llegue a un valor muy alto por ambos lados empezará a sonar a ciencia ficción.
En cambio, si el valor E del intervalo es más modesto, bastará cualquier cosilla moderada no medida para explicar la asociación. Que el valor de p sea minúsculo no ayuda mucho: con un tamaño muestral suficientemente grande se puede obtener una p ridícula para efectos microscópicos que cualquier confusión plausible podría justificar. Por último, no olvidéis que el valor E solo habla de una familia concreta de problemas, los factores de confusión no medidos, por lo que no protege frente al sesgo de selección, los errores de medición, las pérdidas de seguimiento ni las ganas de torturar los datos hasta que digan lo que queremos, factores todos que también debemos controlar cuidadosamente. Pero esa es otra historia…